编者按
SFNT 包装格式是 Apple 为 TrueType 开发的一种字体文件格式。现在这种格式已经被广泛采用为通用的字体格式标准,除了 TrueType,OpenType、WOFF 也采用这种包装格式。
操作 SFNT 字体的库是相当丰富和完善的,比如 Google 开发的库 sfntly (支持 Java 和 C++),这个库在 Chromium 浏览器 中也用作字体相关的处理。
本文对 SFNT 包装格式的内部结构进行简要说明。
本文是系列 “数字化的活字印刷术” 的附属文档。本文中或存在一些基本概念需要提前认知,可前往 主文档 中查看详情。
SFNT 格式文件结构概览
SFNT 包装格式十分简单,由若干张表(下图中蓝色部分)串联构成,第一张表称为 Font Directory。每张表实际是一个数据块。
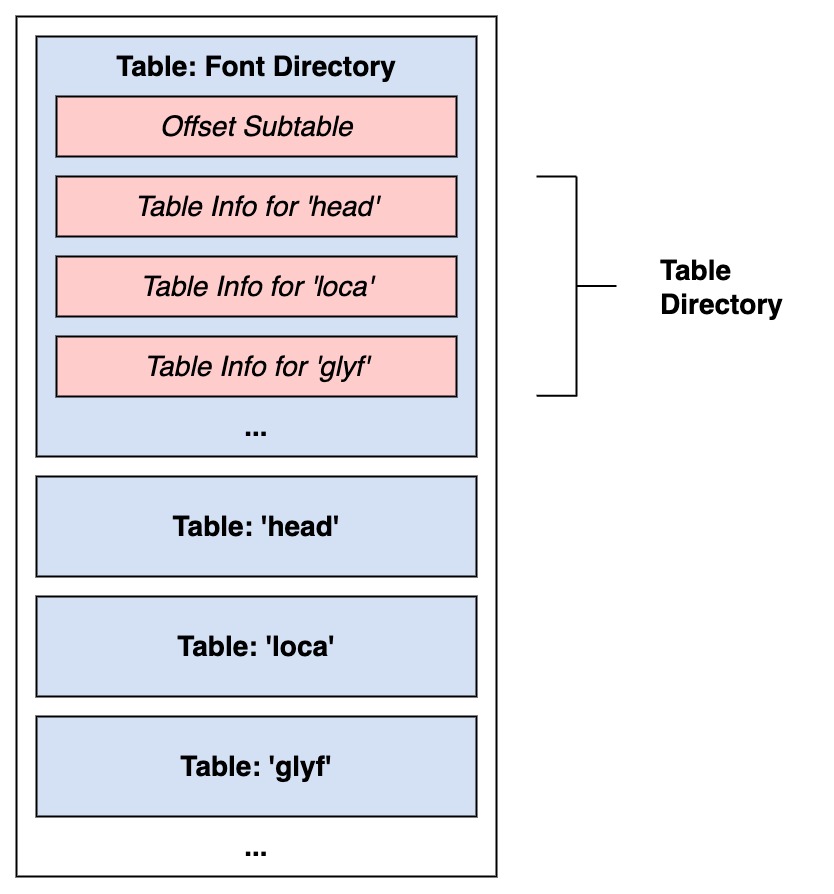 SFNT 包装格式的表结构
SFNT 包装格式的表结构
基本概念
表 (Table)
SFNT 结构的第一张表名为「Font Directory」,是一张特殊的表,其中记录了字体的基本信息和其他表的信息。
除了 Font Directory 外,每张表都有其名字及特定的含义。例如:
- ‘head’ 表中记录了字体的全局信息、版本号等元数据;
- ‘cmap’表(Character Code Mapping)存储了字符编码(Character Code)到字形(Glyph)的映射关系;
- ‘glyf’(Glyph Outline)表是整个字体中最大的表,记录了每个字形(Glyph)的轮廓、指令等数据;
- ‘loca’表(Glyph Location)是位置索引,它存储了各个字符相对于 ‘glyf’ 表头的偏移量;
所有表中的数据都以二进制的方式存储在电脑中,例如 ‘head’ 表在计算机中就是一串二进制数:
1 | from fontTools.ttLib import TTFont |
每个表中二进制资料都有其约定的、独特的解析方法。
字体目录 (Font Directory) 表
字体目录表可分为两个部分:Offset Subtable、Table Directory。
Offset Subtable
此处使用 5 个数字记录了该 SFNT 字体的格式、表的数量,以及一些用于优化搜索速度的字段。
| Type | Name | Description |
|---|---|---|
| uint32 | SFNT type | 0x74727565(即 ASCII ‘true’)表示 Apple TrueType 格式字体;0x00010000 表示 Microsoft、Adobe 的 TrueType 格式字体;0x4F54544F(即 ASCII ‘OTTO’)表示使用 PostScript 轮廓的 OpenType 字体;…… |
| uint16 | numTables | 表的数量 |
| uint16 | searchRange | 用来优化后面表的二分搜索速度:(maximum power of 2 <= numTables)*16 |
| uint16 | entrySelector | 用来优化后面表的二分搜索速度:log2(maximum power of 2 <= numTables) |
| uint16 | rangeShift | 用来优化后面表的二分搜索速度:numTables*16-searchRange |
Table Directory
此处使用一系列串联的表信息结构体(如下所示),描述每一张表的名字、偏移量、长度等信息。
| Type | Name | Description |
|---|---|---|
| uint32 | tag | 表的名字,4 个 ASCII 字符构成,如 ‘head’ ‘glyf’ ‘loca’,不足 4 个字符的表名在尾部用空格补齐 |
| uint32 | checkSum | 表中数据的校验和 |
| uint32 | offset | 该表的数据在该文件中的偏移量 |
| uint32 | length | 该表的实际长度(不含补 0) |
字符相关概念
- 字符集(Character Set)定义了一系列支持的字符,如 GB18030 字符集、Big5 字符集、Unicode 字符集。
- 字符编码(Character Encoding)是指将字符编码成数字的编码规则,例如 ASCII 编码、Unicode 编码、Big5 编码、GB18030 编码。
- 码点、码位、内码(Code Point、Code Position):字符集中的每一个字符都能通过字符编码对应到一个数字,称为码点。
- 「我」字的 Unicode 码点是「U+6211」,GB18030 码点是「CED2」。
- 「A」的 ASCII 码点是 42。

- Unicode 名称(Unicode Name):Unicode 字符集中的每一个码点都拥有一个字符串「名字」
- 「我」字的 Unicode 名称为「CJK UNIFIED IDEOGRAPH-6211」
- 「A」的 Unicode 名称为「LATIN CAPITAL LETTER A」
几张必需表的功能
| Tag | 描述 |
|---|---|
| cmap | 码点对应到 Glyph 的映射表 |
| glyf | 包含每个 Glyph 的轮廓数据 |
| head | 表中记录了字体的全局信息,例如版本号等 |
| hhea | horizontal header (不知道怎么翻译,避免歧义直接用原文档的术语) |
| hmtx | horizontal metrics (不知道怎么翻译,避免歧义直接用原文档的术语) |
| loca | 存储了各个字符相对于 ‘glyf’ 表头的偏移量 |
| maxp | 记录字体对于内存上的一些需求参数 |
| name | 包含了人类可读的相关名称数据,比如字体名称等 |
| post | PostScript相关数据 |
‘head’
此表是一个结构体,包括但不限于以下基本信息:
- 字体版本
- 创建时间、修改时间
- Direction hint
- 所有字型的 x、y 坐标范围
选字的过程:’cmap’、’loca’ 和 ‘glyf’ 表
‘cmap’,’loca’ 和 ‘glyf’ 三张表之间有着映射关系。
‘glyf’表 (Glyph Outline) 是最大的一张表,包括了每个字形的轮廓、指令等数据;
‘cmap’表 (Character Code Mapping) 存储的是字符到字形的映射;
‘loca’表 (Glyph Location) 是位置索引表,它存储了各个字符相对于’glyf’表头的偏移量,’loca’表的存在是为了提升特定字符数据的快速访问速度。
通常的字符映射方法为:由 ‘cmap’ 表中的映射关系,定位到 ‘loca’ 表中存储的字型偏移量,再由 ‘loca’ 表提供的偏移量定位到 ‘glyf’ 表中的字形中,就能获取到字形。
例如中易楷体 simkai.ttf 中,简体汉字「马」的字符映射示意图是:
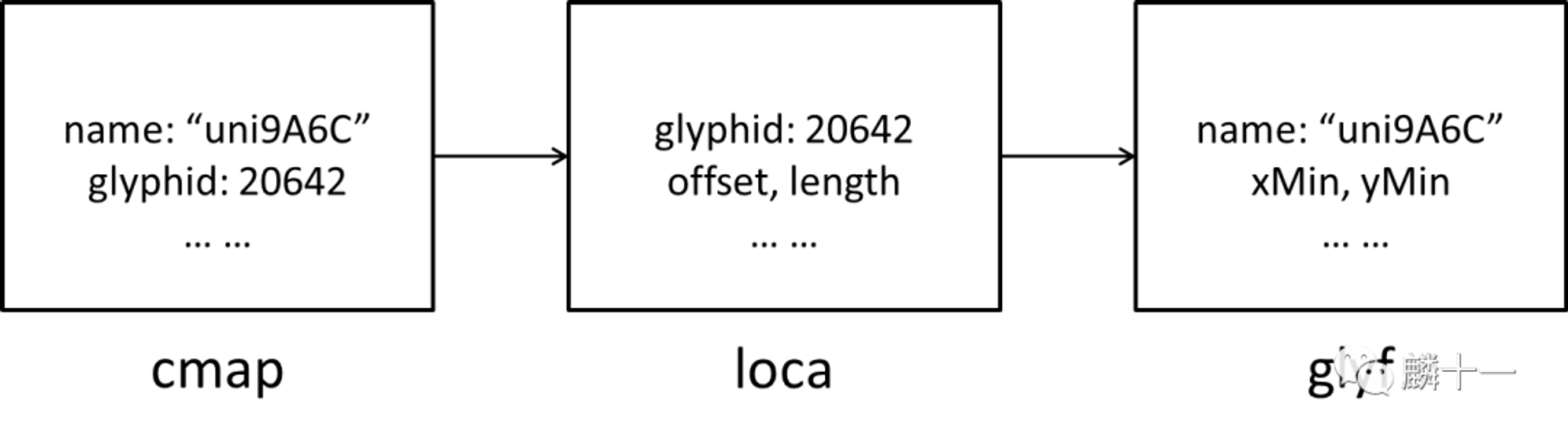
在 ‘cmap’ 表中存储了字符 “马” 的 Unicode 码点 uni9A6C 和字形编号 20642 的对应关系,’loca’表负责通过字形编号 20642 查找到字形 “马” 在 ‘glyf’ 表中的具体位置,’glyf’ 表中存储了“马”的字形数据,例如轮廓线条数,边界框坐标等等。
