编者按
fontconfig 在匹配我们需要的字体时,会先计算字体库中的所有字体与查询的距离,然后采纳其中距离最小(匹配度最高)的字体作为匹配字体。
在 fontconfig 中库函数 FcFontSort、FcFontMatch 都能实现这一需求。本文通过对 FcFontSort 的源码探究揭示了这一匹配过程。
注:为保证易读性,本文贴出的所有代码在遵循基本语义不变的原则上,对 fontconfig 仓库 中的源代码进行了增加、删除、渲染及改写。读者不可认为本文贴出的代码是真正的源代码。
本文是系列 “数字化的活字印刷术” 的附属文档。本文中或存在一些基本概念需要提前认知,可前往 主文档 中查看详情。
名词解释
字体信息(pattern):描述一个字体各方面的全部信息。一串字体信息可由一系列参数构成,参数包括 Family Name、Weight、Size、选用的栅格化方式、支持的语言、字符集等。
字体信息表达式(textual representation for patterns)即一个字体信息的字符串表示,其格式为
<families>-<point sizes>:<name1>=<values1>:<name2>=<values2>...,例如 “Monospace-19:bold“ 表示一个 Family Name 为 Monospace 的 19pt 的加粗字体。查询、查询条件(query):指我们输入到 Fontconfig 的字体查询条件,用 字体信息表达式 来表达,例如 “
Monospace,mono-19:bold“ 表示我们需要找支持 19pt 的默认粗体等距字体。
匹配过程框架
在正式进行距离计算,并根据距离排序之前,FcFontSort 首先会根据配置文件构造一套 候选字体集合。然后,由 FcFontSetSort 函数遍历这个 候选字体集合,计算其中每个字体与我们查询条件的距离。
1 | /// fcmatch.c |
Family Hash 的构造
FcFontSetSort 函数(见「距离计算」中贴出的源码)首先进行一些判空、初始化操作。
在确认行为合法后,该函数会调用 FcCompareDataInit 来构造与查询条件相对应的 Family Hash。
Family Hash 是用户提供的查询条件中的 Family Name 的查询表,key 是 Family Name,value 是 该 Family Name 在查询所提供的 Family Name 列表中第一次出现的位置。
例如,如果我们的查询是 “
sans-serif,sans,serif,sans“,那么生成的 Family Hash 是:{ "sans-serif": 0, "sans": 1, "serif": 2 }
Family Hash 在字体匹配中具有重要作用。在检查某个字体的 Family Name 与我们的查询条件中的 Family Name 是否匹配时,实际上是通过对这张表进行散列查找实现的。
在上面的例子中,如果系统中某个字体的 Family Name 是 "monospace,mono",而由于这两个名字在上述 Family Hash 中都找不到,因此该字体的 Family 距离会很大(Family 的匹配度低);如果某字体的 Family Name 中包含 "sans-serif",则该字体的 Family 距离为 0(匹配度最高)。
从 Family Hash 所使用的散列函数可知,Family Name 的匹配实际上是忽略大小写及忽略空格的。换句话说,monospace、MonoSpace、Monospace、monoSpace、mono space、Mono Space 在匹配 Family Name 时是等效的,但是 monospace、mono、mono-soace 之间则不等效。
1 | /// fcmatch.c |
距离计算
当得到 Family Hash 后, FcFontSetSort 会进行 距离计算,即遍历整个字体库,并计算查询条件(p)与每个字体(new->pattern)的距离。
1 | /// fcmatch.c |
距离向量
计算距离时,会为字体库中每个字体生成一个 距离向量(上面代码中的 new->score),其中每个值是该字体与查询条件在某个指标上(比如 Family、Weight、PointSize)的距离的具体值。
距离向量的维度是 28,其中各个位置与 查询条件的优先级列表(附录 1) 中的具体条件的种类一一对应。例如,该向量中的第 8 个值是该字体与查询条件在 Family Name 上的距离值;第 9 个值是该字体与查询条件在 PostScript Name 上的距离值;第 16 个值是该字体与查询条件在 Weight 上的距离值。
生成距离向量使用的是 FcCompare 函数。该函数只比较查询条件和候选字体中共有的字体信息,并计算它们的距离;对于那些查询条件中指定了、但是候选字体信息中没有的信息,就不去进行比较,并设置他们的默认距离为 0(即匹配度高)。
例如,查询条件中指定了 "antialias=true",但是候选字体并未提供这一信息,则该项比较会跳过,并设置默认距离为 0。
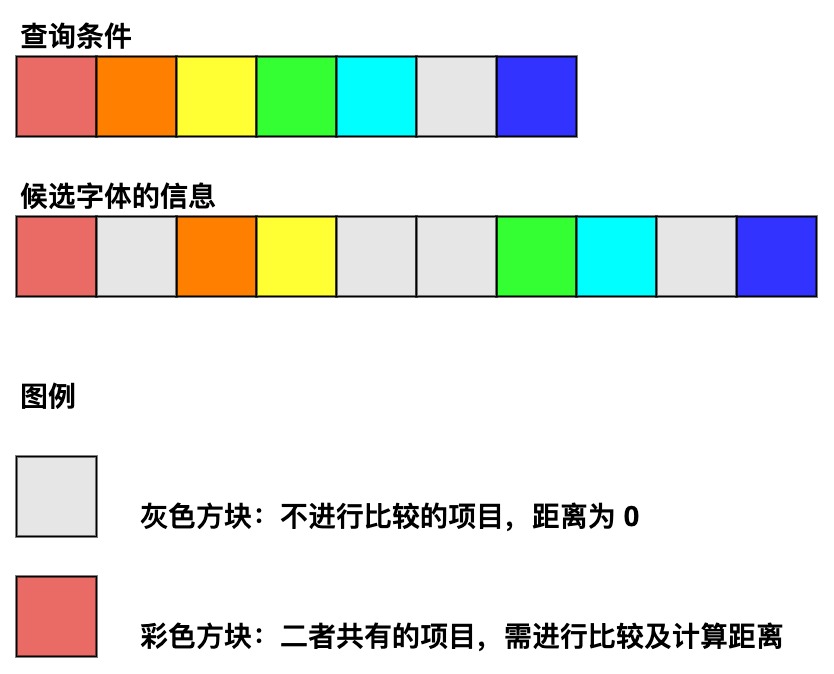
由于 Family 项目较为特殊——每个字体都分为 strong family、weak family 两组值,不像其他参数那样只有一组值,因此,Family 项目需要单独拧出来进行距离计算。
Family 的距离计算函数为 FcCompareFamilies,其他项目的距离计算函数为 FcCompareValueList。
1 | /// fcmatch.c |
Family 的距离计算函数
Fontconfig 计算两个字体的 Family 的距离(匹配度)使用的函数是 FcCompareFamilies。为简单起见,在本节叙述 Family 的距离计算函数时,对 strong family、weak family 不予区分。
源码定义:候选字体的 Family 与查询条件的 Family 的距离,等于 该候选字体的 Family 在查询条件的 Family 列表中第一次出现的位置的最小值。
例如,假设我们的查询条件是 "sans-serif,sans,sansserif,Helvetica,Arial":
如果某字体的 Family 是
"serif,Times,TimesNewRoman",由于其中没有任何 Family 和我们的查询条件相匹配,因此其 Family 距离为 1e99(即 Family 匹配度极低);如果某字体的 Family 是
"Heivetica,Sans,sans serif":- Helvetica 在查询条件中第一次出现的位置是 3,Sans 是 1,Sans serif 没有出现过;
- 取上述 Family 在查询条件中 第一次出现的位置的最小值(1)作为 Family 的距离。
由于 Family Hash 表中的 value 正好记录的是 Family 在查询条件中第一次出现的位置,所以上述目的可以通过查 Family Hash 表实现。
1 | /// fcmatch.c |
普通项目的距离计算函数
包括 Family 在内,所有字体信息项目都允许有多个值,基本数据结构都是 List。Fontconfig 计算两个 List 的距离(匹配度)使用的函数是 FcCompareValueList。
具体做法是将两个 List 中的每个值进行两两比较,比较过程中计算加权距离,最后输出所有加权距离最小值。在加权距离的计算中,两值的绝对距离值的权重最大,同时,两值在 List 中的先后顺序也参与权重计算。
由于每个项目的数据类型不同,其绝对距离计算方式不一样,如数字型项目(如 FontVersion)的绝对距离为差的绝对值,字符串型项目(如 Style 等)的绝对距离采用字符串比较函数(类似 strcmp)来计算。各项目的类型、绝对距离计算方式见 附录 2。
【例】如果我们的查询条件是 **”fontversion=80,85,90”**,某字体提供的 FontVersion 是 **”fontversion=90,95”**,则 FontVersion 的加权距离的计算过程为:
- 参与计算权重的值对为 (80,90)、(80,95)、(85,90)、(85,95)、(90,90)、(90,95),即 3x2 = 6 个。
- 每个值对计算加权距离。
- fontversion 的值的类型为 int,其 绝对距离值 为两值的绝对差值 |v2 - v1|。
- (80,90) 的绝对距离为 10,加权距离为 10 * 1000 + 0 * 100 + 0 = 10000
- (80,95) 的绝对距离为 5,加权距离为 15 * 1000 + 0 * 100 + 1 = 15001
- (90,90) 的绝对距离为 0,加权距离为 0 * 1000 + 2 * 100 + 0 = 200
- (90,95) 的绝对距离为 5,加权距离为 5 * 1000 + 2 * 100 + 1 = 5201
- 最小加权距离为 200,因此 FontVersion 的加权距离为 200。
1 | /// fcmatch.c |
排序
计算距离结束后,如果需要将全部字体按照其与查询的距离排序,使用的是快速排序算法。排序时采用的比较两个字体整体距离值的函数是 FcSortCompare。
- 按照 优先级顺序,该函数从优先级最大的距离值开始。当找到第一个两字体不相等的距离时,距离值较大的那个字体,我们就说它总距离更大(匹配度更低);
- 如果两个字体的整个距离向量都相等,则两个字体与查询条件的距离相等。
【例】如果字体 A 的距离向量是 [0, 1, 1, 0, …],字体 B 的距离向量是 [0, 1, 0, 4, …],则:
- 字体 A 与字体 B 的第 0、1 个距离相等,第 2 个距离不相等;
- 由于 A[2] > B[2],因此我们说字体 A 与查询条件的距离较大,匹配度比 B 更低。
1 | /// fcmatch.c |
唯一匹配值的取得
在进行字体匹配时,根据查询条件,我们希望匹配出唯一的、匹配度最高的字体。但是距离计算过程中,可能出现距离向量相等的情况,这样距离值最小(匹配度最高)的字体可能存在多个。
事实上 Fontconfig 没有对于这种情况做特殊处理。为了能够返回唯一匹配字体, Fontconfig 在执行 Match 时最后输出的匹配度最高的字体,是字体库中第一个找到的距离值最小的字体。
1 | /// fcmatch.c |
Appendices
附录 1:字体查询条件中各项字体参数及其优先级列表
源码 在此。
1 | typedef enum _FcMatcherPriority { |
附录 2:各项字体参数的数据类型及比较函数
源码 在此。
1 | /// fcobjs.h |
